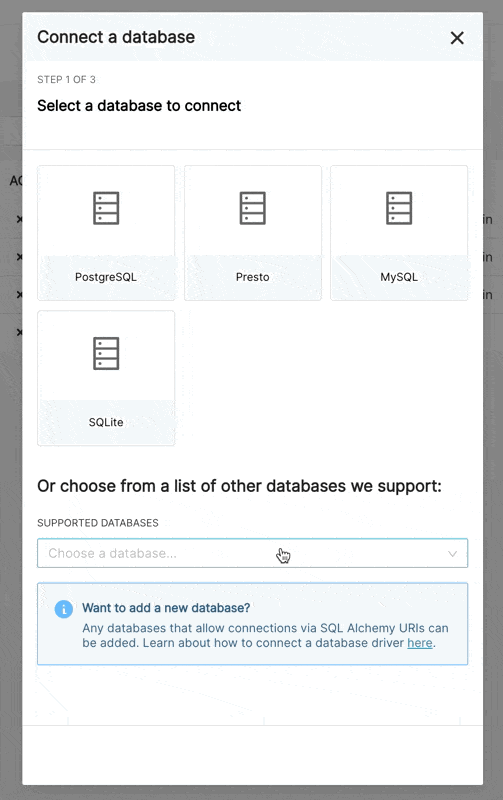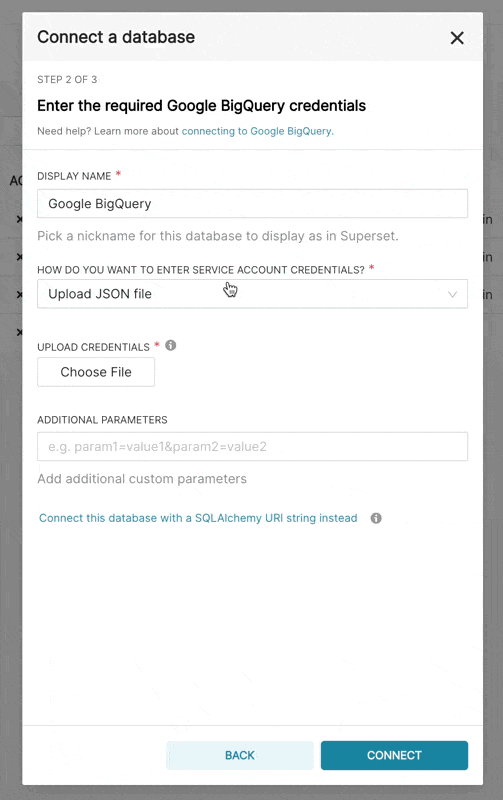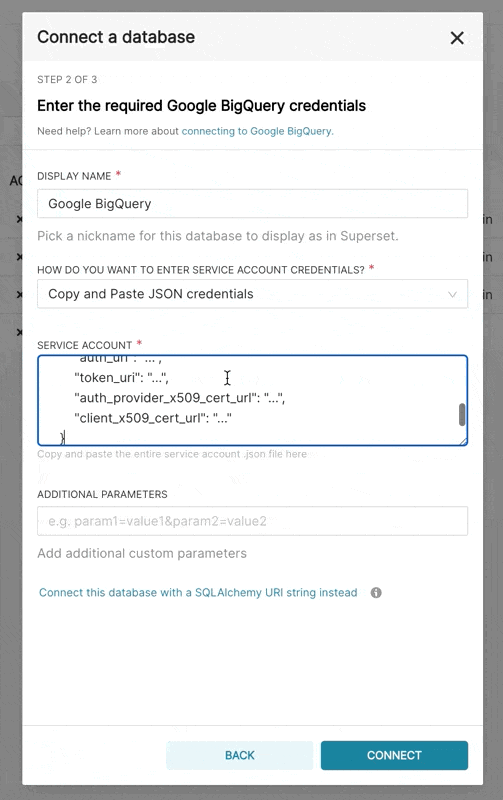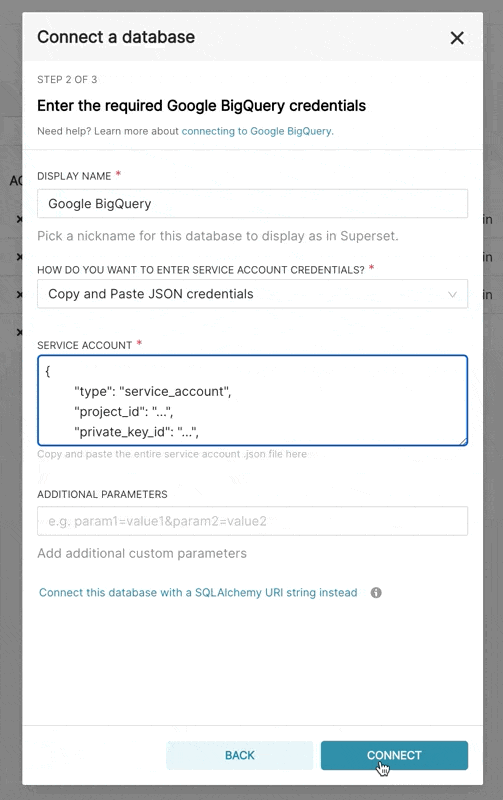
连接到数据库
Superset 不附带数据库连接功能。将 Superset 连接到数据库的主要步骤是**在您的环境中安装适当的数据库驱动程序**。
您需要为您想要用作元数据数据库的数据库安装所需的包,以及连接到您希望通过 Superset 访问的数据库所需的包。有关设置 Superset 元数据数据库的信息,请参阅安装文档(Docker Compose、Kubernetes)
本文档旨在提供常用数据库引擎的不同驱动程序的指针。
安装数据库驱动程序
Superset 需要为每个您想连接的数据库引擎安装一个 Python DB-API 数据库驱动程序和一个 SQLAlchemy 方言。
您可以在此处阅读更多关于如何将新的数据库驱动程序安装到您的 Superset 配置中的信息。
支持的数据库和依赖项
下面列出了一些推荐的包。请参阅 pyproject.toml 以获取与 Superset 兼容的版本。
数据库 | PyPI 包 | 连接字符串 |
|---|---|---|
| AWS Athena | pip install pyathena[pandas] , pip install PyAthenaJDBC | awsathena+rest://{access_key_id}:{access_key}@athena.{region}.amazonaws.com/{schema}?s3_staging_dir={s3_staging_dir}&... |
| AWS DynamoDB | pip install pydynamodb | dynamodb://{access_key_id}:{secret_access_key}@dynamodb.{region_name}.amazonaws.com?connector=superset |
| AWS Redshift | pip install sqlalchemy-redshift | redshift+psycopg2://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name> |
| Apache Doris | pip install pydoris | doris://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database> |
| Apache Drill | pip install sqlalchemy-drill | drill+sadrill://<username>:<password>@<host>:<port>/<storage_plugin>, 通常有用: ?use_ssl=True/False |
| Apache Druid | pip install pydruid | druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql |
| Apache Hive | pip install pyhive | hive://hive@{hostname}:{port}/{database} |
| Apache Impala | pip install impyla | impala://{hostname}:{port}/{database} |
| Apache Kylin | pip install kylinpy | kylin://<username>:<password>@<hostname>:<port>/<project>?<param1>=<value1>&<param2>=<value2> |
| Apache Pinot | pip install pinotdb | pinot://BROKER:5436/query?server=http://CONTROLLER:5983/ |
| Apache Solr | pip install sqlalchemy-solr | solr://{username}:{password}@{hostname}:{port}/{server_path}/{collection} |
| Apache Spark SQL | pip install pyhive | hive://hive@{hostname}:{port}/{database} |
| Ascend.io | pip install impyla | ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true |
| Azure MS SQL | pip install pymssql | mssql+pymssql://UserName@presetSQL:TestPassword@presetSQL.database.windows.net:1433/TestSchema |
| ClickHouse | pip install clickhouse-connect | clickhousedb://{username}:{password}@{hostname}:{port}/{database} |
| CockroachDB | pip install cockroachdb | cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable |
| Couchbase | pip install couchbase-sqlalchemy | couchbase://{username}:{password}@{hostname}:{port}?truststorepath={ssl certificate path} |
| CrateDB | | pip install sqlalchemy-cratedb |
| Denodo | pip install denodo-sqlalchemy | denodo://{username}:{password}@{hostname}:{port}/{database} |
| Dremio | pip install sqlalchemy_dremio | dremio+flight://{username}:{password}@{host}:32010, 通常有用: ?UseEncryption=true/false。对于旧版 ODBC: dremio+pyodbc://{username}:{password}@{host}:31010 |
| Elasticsearch | pip install elasticsearch-dbapi | elasticsearch+http://{user}:{password}@{host}:9200/ |
| Exasol | pip install sqlalchemy-exasol | exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC |
| Google BigQuery | pip install sqlalchemy-bigquery | bigquery://{project_id} |
| Google Sheets | pip install shillelagh[gsheetsapi] | gsheets:// |
| Firebolt | pip install firebolt-sqlalchemy | firebolt://{client_id}:{client_secret}@{database}/{engine_name}?account_name={name} |
| Hologres | pip install psycopg2 | postgresql+psycopg2://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| IBM Db2 | pip install ibm_db_sa | db2+ibm_db:// |
| IBM Netezza Performance Server | pip install nzalchemy | netezza+nzpy://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| MySQL | pip install mysqlclient | mysql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| OceanBase | pip install oceanbase_py | oceanbase://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| Oracle | pip install cx_Oracle | oracle://<username>:<password>@<hostname>:<port> |
| Parseable | pip install sqlalchemy-parseable | parseable://<UserName>:<DBPassword>@<Database Host>/<Stream Name> |
| PostgreSQL | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| Presto | pip install pyhive | presto://{username}:{password}@{hostname}:{port}/{database} |
| Rockset | pip install rockset-sqlalchemy | rockset://<api_key>:@<api_server> |
| SAP Hana | pip install hdbcli sqlalchemy-hana 或 pip install apache_superset[hana] | hana://{username}:{password}@{host}:{port} |
| SingleStore | pip install sqlalchemy-singlestoredb | singlestoredb://{username}:{password}@{host}:{port}/{database} |
| StarRocks | pip install starrocks | starrocks://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database> |
| Snowflake | pip install snowflake-sqlalchemy | snowflake://{user}:{password}@{account}.{region}/{database}?role={role}&warehouse={warehouse} |
| SQLite | 无需额外库 | sqlite://path/to/file.db?check_same_thread=false |
| SQL Server | pip install pymssql | mssql+pymssql://<Username>:<Password>@<Host>:<Port-default:1433>/<Database Name> |
| TDengine | pip install taospy pip install taos-ws-py | taosws://<user>:<password>@<host>:<port> |
| Teradata | pip install teradatasqlalchemy | teradatasql://{user}:{password}@{host} |
| TimescaleDB | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>:<Port>/<Database Name> |
| Trino | pip install trino | trino://{username}:{password}@{hostname}:{port}/{catalog} |
| Vertica | pip install sqlalchemy-vertica-python | vertica+vertica_python://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| YDB | pip install ydb-sqlalchemy | ydb://{host}:{port}/{database_name} |
| YugabyteDB | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
请注意,Superset 支持许多其他数据库,主要标准是存在一个功能性的 SQLAlchemy 方言和 Python 驱动程序。搜索关键词“sqlalchemy + (数据库名称)”应该能帮助您找到正确的地方。
如果您的数据库或数据引擎不在列表中,但存在 SQL 接口,请在 Superset GitHub 仓库上提交一个问题,以便我们着手记录和支持它。
如果您想为 Superset 集成构建数据库连接器,请阅读以下教程。
在 Docker 镜像中安装驱动程序
Superset 需要为每个您想连接的额外数据库类型安装一个 Python 数据库驱动程序。
在此示例中,我们将逐步介绍如何安装 MySQL 连接器库。连接器库的安装过程对所有额外库都是相同的。
1. 确定您需要的驱动程序
查阅数据库驱动程序列表,找到连接到您的数据库所需的 PyPI 包。在此示例中,我们连接到 MySQL 数据库,因此我们需要 mysqlclient 连接器库。
2. 在容器中安装驱动程序
我们需要将 mysqlclient 库安装到 Superset docker 容器中(无论是否安装在主机上)。我们可以使用 docker exec -it <container_name> bash 进入正在运行的容器,并在其中运行 pip install mysqlclient,但这不会永久保存。
为了解决这个问题,Superset 的 docker compose 部署使用了 requirements-local.txt 文件的约定。此文件中列出的所有包都将在运行时从 PyPI 安装到容器中。出于本地开发目的,此文件将被 Git 忽略。
在包含 compose.yml 或 compose-non-dev.yml 文件的目录中,创建一个名为 docker 的子目录,并在其中创建 requirements-local.txt 文件。
# Run from the repo root:
touch ./docker/requirements-local.txt
添加上一步中确定的驱动程序。您可以使用文本编辑器或通过命令行操作,例如
echo "mysqlclient" >> ./docker/requirements-local.txt
如果您正在运行一个标准的(非定制的)Superset 镜像,您就完成了。使用 docker compose -f compose-non-dev.yml up 启动 Superset,驱动程序应该已经存在。
您可以通过使用 docker exec -it <container_name> bash 进入正在运行的容器并运行 pip freeze 来检查其是否存在。PyPI 包应该存在于打印列表中。
如果您正在运行一个定制的 docker 镜像,请重建您的本地镜像,将新驱动程序内置其中
docker compose build --force-rm
Docker 镜像重建完成后,通过运行 docker compose up 重新启动 Superset。
3. 连接到 MySQL
现在您已经在容器中安装了 MySQL 驱动程序,您应该能够通过 Superset Web UI 连接到您的数据库。
作为管理员用户,转到“设置”->“数据:数据库连接”,然后单击“+数据库”按钮。从那里,按照使用数据库连接 UI 页面上的步骤操作。
查阅 Superset 文档中特定数据库类型的页面,以确定您需要输入的连接字符串和任何其他参数。例如,在MySQL 页面上,我们看到连接到本地 MySQL 数据库的连接字符串因设置是在 Linux 还是 Mac 上运行而异。
单击“测试连接”按钮,应该会弹出一个消息,显示“连接良好!”。
4. 故障排除
如果测试失败,请检查您的 docker 日志以查找错误消息。Superset 使用 SQLAlchemy 连接到数据库;为了解决数据库连接字符串的问题,您可以尝试在 Superset 应用程序容器或主机环境中启动 Python,并尝试直接连接到所需的数据库并获取数据。这在隔离问题时排除了 Superset。
对您希望 Superset 连接的每种数据库类型重复此过程。
数据库特定说明
Ascend.io
推荐的 Ascend.io 连接器库是 impyla。
预期的连接字符串格式如下
ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true
Apache Doris
sqlalchemy-doris 库是推荐通过 SQLAlchemy 连接到 Apache Doris 的方式。
您需要以下设置值来形成连接字符串
- User: 用户名
- Password: 密码
- Host: Doris FE 主机
- Port: Doris FE 端口
- Catalog: 目录名称
- Database: 数据库名称
连接字符串如下所示
doris://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database>
AWS Athena
PyAthenaJDBC
PyAthenaJDBC 是 Amazon Athena JDBC 驱动程序 的 Python DB 2.0 兼容包装器。
Amazon Athena 的连接字符串如下
awsathena+jdbc://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
请注意,在形成连接字符串时,您需要进行转义和编码,如下所示
s3://... -> s3%3A//...
PyAthena
您还可以使用 PyAthena 库(无需 Java)和以下连接字符串
awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
PyAthena 库还允许假定一个特定的 IAM 角色,您可以通过在 Superset 的 Athena 数据库连接 UI 的“高级” -> “其他” -> “引擎参数”下添加以下参数来定义该角色。
{
"connect_args": {
"role_arn": "<role arn>"
}
}
AWS DynamoDB
PyDynamoDB
PyDynamoDB 是用于 Amazon DynamoDB 的 Python DB API 2.0 (PEP 249) 客户端。
Amazon DynamoDB 的连接字符串如下
dynamodb://{aws_access_key_id}:{aws_secret_access_key}@dynamodb.{region_name}.amazonaws.com:443?connector=superset
要获取更多文档,请访问:PyDynamoDB WIKI。
AWS Redshift
sqlalchemy-redshift 库是推荐通过 SQLAlchemy 连接到 Redshift 的方式。
此方言需要 redshift_connector 或 psycopg2 才能正常工作。
您需要设置以下值来形成连接字符串
- User Name: 用户名
- Password: 数据库密码
- Database Host: AWS 端点
- Database Name: 数据库名称
- Port: 默认 5439
psycopg2
SQLALCHEMY URI 如下所示
redshift+psycopg2://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name>
redshift_connector
SQLALCHEMY URI 如下所示
redshift+redshift_connector://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name>
使用基于 IAM 的凭证连接 Redshift 集群
Amazon Redshift 集群还支持生成基于 IAM 的临时数据库用户凭证。
您的 Superset 应用的 IAM 角色应该拥有调用 redshift:GetClusterCredentials 操作的权限。
您必须在 Superset 的 Redshift 数据库连接 UI 的“高级” -> “其他” -> “引擎参数”下定义以下参数。
{"connect_args":{"iam":true,"database":"<database>","cluster_identifier":"<cluster_identifier>","db_user":"<db_user>"}}
并且 SQLALCHEMY URI 应设置为 redshift+redshift_connector://
使用基于 IAM 的凭证连接 Redshift Serverless
Redshift Serverless 支持使用 IAM 角色进行连接。
您的 Superset 应用程序的 IAM 角色应在 Redshift Serverless 工作组上具有 redshift-serverless:GetCredentials 和 redshift-serverless:GetWorkgroup 权限。
您必须在 Superset 的 Redshift 数据库连接 UI 的“高级” -> “其他” -> “引擎参数”下定义以下参数。
{"connect_args":{"iam":true,"is_serverless":true,"serverless_acct_id":"<aws account number>","serverless_work_group":"<redshift work group>","database":"<database>","user":"IAMR:<superset iam role name>"}}
ClickHouse
要将 ClickHouse 与 Superset 结合使用,您需要安装 clickhouse-connect Python 库
如果使用 Docker Compose 运行 Superset,请将以下内容添加到您的 ./docker/requirements-local.txt 文件中
clickhouse-connect>=0.6.8
ClickHouse 推荐的连接器库是 clickhouse-connect。
预期的连接字符串格式如下
clickhousedb://<user>:<password>@<host>:<port>/<database>[?options…]clickhouse://{username}:{password}@{hostname}:{port}/{database}
以下是一个真实连接字符串的具体示例
clickhousedb://demo:demo@github.demo.trial.altinity.cloud/default?secure=true
如果您在本地计算机上使用 Clickhouse,您可以使用不带密码的默认用户使用的 http 协议 URL(并且不加密连接)
clickhousedb:///default
CockroachDB
推荐的 CockroachDB 连接器库是 sqlalchemy-cockroachdb。
预期的连接字符串格式如下
cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable
Couchbase
Couchbase 的 Superset 连接旨在支持两种服务:Couchbase Analytics 和 Couchbase Columnar。Couchbase 推荐的连接器库是 couchbase-sqlalchemy。
pip install couchbase-sqlalchemy
预期的连接字符串格式如下
couchbase://{username}:{password}@{hostname}:{port}?truststorepath={certificate path}?ssl={true/false}
CrateDB
CrateDB 的连接器库是 sqlalchemy-cratedb。我们建议将以下项目添加到您的 requirements.txt 文件中
sqlalchemy-cratedb>=0.40.1,<1
用于连接到 localhost 上的 CrateDB Self-Managed(用于评估目的)的 SQLAlchemy 连接字符串如下所示
crate://crate@127.0.0.1:4200
用于连接到 CrateDB Cloud 的 SQLAlchemy 连接字符串如下所示
crate://<username>:<password>@<clustername>.cratedb.net:4200/?ssl=true
在本地使用 Docker Compose 设置 Superset 时,请按照此处的步骤安装 CrateDB 连接器包。
echo "sqlalchemy-cratedb" >> ./docker/requirements-local.txt
Databend
Databend 推荐的连接器库是 databend-sqlalchemy。Superset 已经在 databend-sqlalchemy>=0.2.3 上进行了测试。
推荐的连接字符串是
databend://{username}:{password}@{host}:{port}/{database_name}
以下是 Superset 连接到 Databend 数据库的连接字符串示例
databend://user:password@localhost:8000/default?secure=false
Databricks
Databricks 现在提供了一个原生的 DB API 2.0 驱动程序 databricks-sql-connector,可以与 sqlalchemy-databricks 方言一起使用。您可以同时安装它们,使用
pip install "apache-superset[databricks]"
要使用 Hive 连接器,您需要集群的以下信息
- 服务器主机名
- 端口
- HTTP 路径
这些可以在“配置” -> “高级选项” -> “JDBC/ODBC”下找到。
您还需要一个来自“设置” -> “用户设置” -> “访问令牌”的访问令牌。
获得所有这些信息后,添加一个类型为“Databricks Native Connector”的数据库,并使用以下 SQLAlchemy URI
databricks+connector://token:{access_token}@{server_hostname}:{port}/{database_name}
您还需要将以下配置添加到“其他” -> “引擎参数”中,并包含您的 HTTP 路径
{
"connect_args": {"http_path": "sql/protocolv1/o/****"}
}
旧版驱动程序
Superset 最初使用 databricks-dbapi 连接到 Databricks。如果您在使用官方 Databricks 连接器时遇到问题,您可能需要尝试一下
pip install "databricks-dbapi[sqlalchemy]"
使用 databricks-dbapi 连接到 Databricks 有两种方式:使用 Hive 连接器或 ODBC 连接器。两种方式工作方式类似,但只有 ODBC 可以用于连接到 SQL 端点。
Hive
要在 Superset 中连接到 Hive 集群,请添加类型为“Databricks Interactive Cluster”的数据库,并使用以下 SQLAlchemy URI
databricks+pyhive://token:{access_token}@{server_hostname}:{port}/{database_name}
您还需要将以下配置添加到“其他” -> “引擎参数”中,并包含您的 HTTP 路径
{"connect_args": {"http_path": "sql/protocolv1/o/****"}}
ODBC
对于 ODBC,您首先需要为您的平台安装 ODBC 驱动程序。
对于常规连接,根据您的用例,选择数据库为“Databricks Interactive Cluster”或“Databricks SQL Endpoint”后,将此用作 SQLAlchemy URI
databricks+pyodbc://token:{access_token}@{server_hostname}:{port}/{database_name}
对于连接参数
{"connect_args": {"http_path": "sql/protocolv1/o/****", "driver_path": "/path/to/odbc/driver"}}
驱动程序路径应为
/Library/simba/spark/lib/libsparkodbc_sbu.dylib(Mac OS)/opt/simba/spark/lib/64/libsparkodbc_sb64.so(Linux)
要连接到 SQL 端点,您需要使用端点的 HTTP 路径
{"connect_args": {"http_path": "/sql/1.0/endpoints/****", "driver_path": "/path/to/odbc/driver"}}
Denodo
推荐的 Denodo 连接器库是 denodo-sqlalchemy。
预期的连接字符串格式如下(默认端口为 9996)
denodo://{username}:{password}@{hostname}:{port}/{database}
Dremio
Dremio 推荐的连接器库是 sqlalchemy_dremio。
ODBC 的预期连接字符串格式如下(默认端口为 31010)
dremio+pyodbc://{username}:{password}@{host}:{port}/{database_name}/dremio?SSL=1
Arrow Flight 的预期连接字符串格式如下(Dremio 4.9.1+,默认端口为 32010)
dremio+flight://{username}:{password}@{host}:{port}/dremio
Dremio 的这篇博客文章提供了一些将 Superset 连接到 Dremio 的额外有用说明。
Apache Drill
SQLAlchemy
连接 Apache Drill 的推荐方式是通过 SQLAlchemy。您可以使用 sqlalchemy-drill 包。
完成后,您可以通过两种方式连接到 Drill,即通过 REST 接口或通过 JDBC。如果通过 JDBC 连接,您必须安装 Drill JDBC 驱动程序。
Drill 的基本连接字符串如下所示
drill+sadrill://<username>:<password>@<host>:<port>/<storage_plugin>?use_ssl=True
要连接到在嵌入式模式下运行在本地机器上的 Drill,您可以使用以下连接字符串
drill+sadrill://:8047/dfs?use_ssl=False
JDBC
通过 JDBC 连接到 Drill 更复杂,我们建议遵循本教程。
连接字符串如下
drill+jdbc://<username>:<password>@<host>:<port>
ODBC
我们建议阅读 Apache Drill 文档并阅读 GitHub README,以了解如何通过 ODBC 使用 Drill。
Apache Druid
Superset 附带了一个原生 Druid 连接器(在 DRUID_IS_ACTIVE 标志后面),但它正在逐渐被 pydruid 库中提供的 SQLAlchemy / DBAPI 连接器取代。
连接字符串如下
druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql
以下是此连接字符串关键组件的细分
User: 连接数据库所需的凭据的用户名部分Password: 连接数据库所需的凭据的密码部分Host: 运行数据库的主机机器的 IP 地址(或 URL)Port: 主机机器上数据库运行的特定端口
自定义 Druid 连接
添加 Druid 连接时,您可以在**添加数据库**表单中通过几种不同的方式自定义连接。
自定义证书
在配置新的 Druid 数据库连接时,您可以在**根证书**字段中添加证书

使用自定义证书时,pydruid 将自动使用 https 方案。
禁用 SSL 验证
要禁用 SSL 验证,请在**额外**字段中添加以下内容
engine_params:
{"connect_args":
{"scheme": "https", "ssl_verify_cert": false}}
聚合
常用的聚合或 Druid 度量可以在 Superset 中定义和使用。第一个更简单的用例是使用数据源编辑视图中暴露的复选框矩阵(**源 -> Druid 数据源 -> [您的数据源] -> 编辑 -> [选项卡] 列出 Druid 列**)。
勾选“分组”和“可过滤”复选框将使列在“探索”视图中出现在相关下拉列表中。勾选“计数”、“去重”、“最小值”、“最大值”或“求和”将创建新的度量,这些度量将在保存数据源后出现在**列出 Druid 度量**选项卡中。
通过编辑这些指标,您会注意到它们的 JSON 元素对应于 Druid 聚合定义。您可以根据 Druid 文档,从“列出 Druid 指标”选项卡手动创建自己的聚合。
后聚合
Druid 支持后聚合,这在 Superset 中也有效。您所需要做的就是创建一个度量,就像您手动创建聚合一样,但将 Metric Type 指定为 postagg。然后,您必须在 JSON 字段中提供有效的 json 后聚合定义(如 Druid 文档中所述)。
Elasticsearch
Elasticsearch 推荐的连接器库是 elasticsearch-dbapi。
Elasticsearch 的连接字符串如下所示
elasticsearch+http://{user}:{password}@{host}:9200/
使用 HTTPS
elasticsearch+https://{user}:{password}@{host}:9200/
Elasticsearch 的默认行数限制为 10000 行,因此您可以在集群上增加此限制,或在 Superset 的配置中设置行数限制
ROW_LIMIT = 10000
例如,您可以在 SQL Lab 中查询多个索引
SELECT timestamp, agent FROM "logstash"
但是,要使用多索引可视化,您需要在集群上创建一个别名索引
POST /_aliases
{
"actions" : [
{ "add" : { "index" : "logstash-**", "alias" : "logstash_all" } }
]
}
然后使用别名 logstash_all 注册您的表
时区
默认情况下,Superset 使用 UTC 时区进行 Elasticsearch 查询。如果您需要指定时区,请编辑您的数据库,并在“其他” > “引擎参数”中输入您指定时区的设置。
{
"connect_args": {
"time_zone": "Asia/Shanghai"
}
}
关于时区问题,需要注意的另一个问题是,在 elasticsearch7.8 之前,如果您想将字符串转换为 DATETIME 对象,您需要使用 CAST 函数,但此函数不支持我们的 time_zone 设置。因此建议升级到 elasticsearch7.8 之后的版本。在 elasticsearch7.8 之后,您可以使用 DATETIME_PARSE 函数来解决此问题。DATETIME_PARSE 函数支持我们的 time_zone 设置,并且在这里您需要在“其他” > “版本”设置中填写您的 elasticsearch 版本号。superset 将使用 DATETIME_PARSE 函数进行转换。
禁用 SSL 验证
要禁用 SSL 验证,请在**SQLALCHEMY URI**字段中添加以下内容
elasticsearch+https://{user}:{password}@{host}:9200/?verify_certs=False
Exasol
Exasol 推荐的连接器库是 sqlalchemy-exasol。
Exasol 的连接字符串如下所示
exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC
Firebird
Firebird 推荐的连接器库是 sqlalchemy-firebird。Superset 已经在 sqlalchemy-firebird>=0.7.0, <0.8 上进行了测试。
推荐的连接字符串是
firebird+fdb://{username}:{password}@{host}:{port}//{path_to_db_file}
以下是 Superset 连接到本地 Firebird 数据库的连接字符串示例
firebird+fdb://SYSDBA:masterkey@192.168.86.38:3050//Library/Frameworks/Firebird.framework/Versions/A/Resources/examples/empbuild/employee.fdb
Firebolt
Firebolt 推荐的连接器库是 firebolt-sqlalchemy。
推荐的连接字符串是
firebolt://{username}:{password}@{database}?account_name={name}
or
firebolt://{username}:{password}@{database}/{engine_name}?account_name={name}
也可以使用服务账户进行连接
firebolt://{client_id}:{client_secret}@{database}?account_name={name}
or
firebolt://{client_id}:{client_secret}@{database}/{engine_name}?account_name={name}
Google BigQuery
BigQuery 推荐的连接器库是 sqlalchemy-bigquery。
安装 BigQuery 驱动程序
按照此处的步骤了解如何在通过 docker compose 本地设置 Superset 时安装新的数据库驱动程序。
echo "sqlalchemy-bigquery" >> ./docker/requirements-local.txt
连接到 BigQuery
在 Superset 中添加新的 BigQuery 连接时,您需要添加 GCP 服务账户凭据文件(JSON 格式)。
- 通过 Google Cloud Platform 控制面板创建您的服务账户,授予其访问相应 BigQuery 数据集的权限,并下载该服务账户的 JSON 配置文件。
- 在 Superset 中,您可以上传该 JSON 文件,或者以以下格式添加 JSON blob(这应该是您的凭据 JSON 文件的内容)
{
"type": "service_account",
"project_id": "...",
"private_key_id": "...",
"private_key": "...",
"client_email": "...",
"client_id": "...",
"auth_uri": "...",
"token_uri": "...",
"auth_provider_x509_cert_url": "...",
"client_x509_cert_url": "..."
}
-
此外,也可以通过 SQLAlchemy URI 进行连接
BigQuery 的连接字符串如下
bigquery://{project_id}转到**高级**选项卡,在数据库配置表单的**安全额外**字段中添加一个 JSON blob,格式如下
{
"credentials_info": <contents of credentials JSON file>
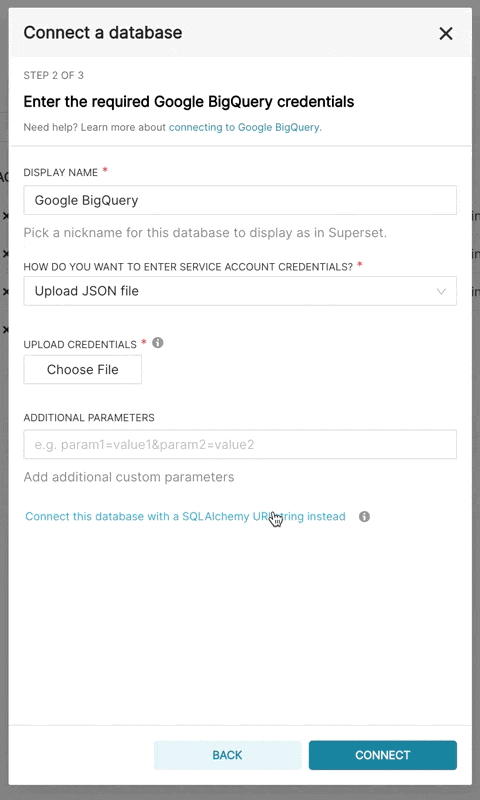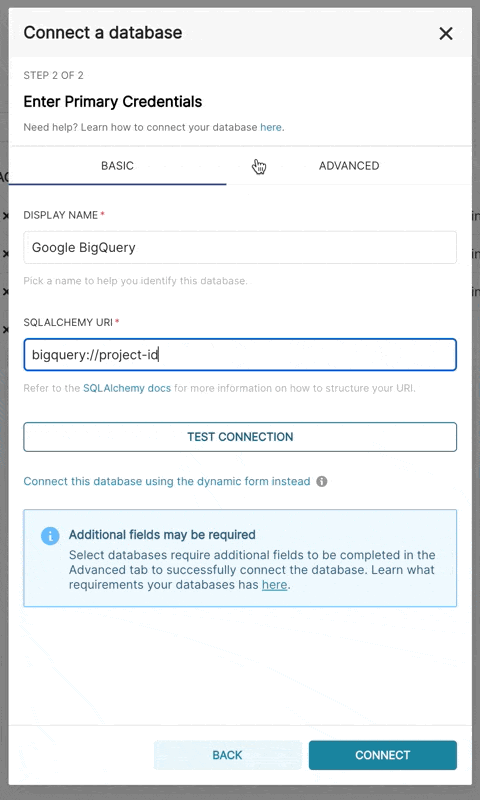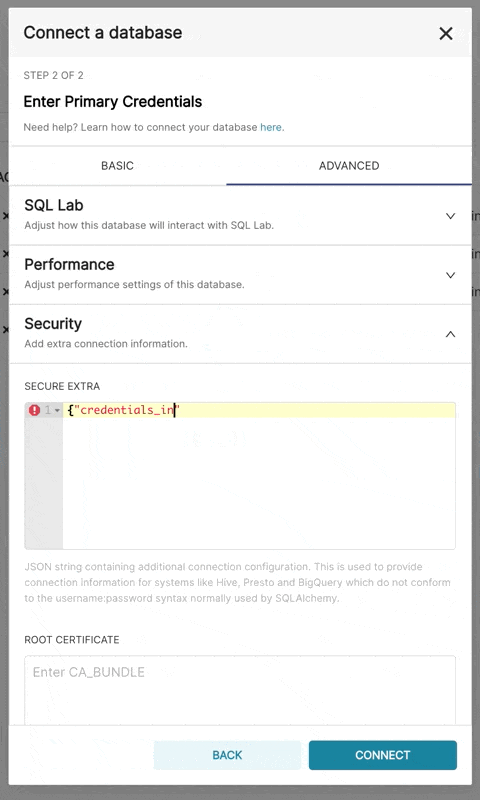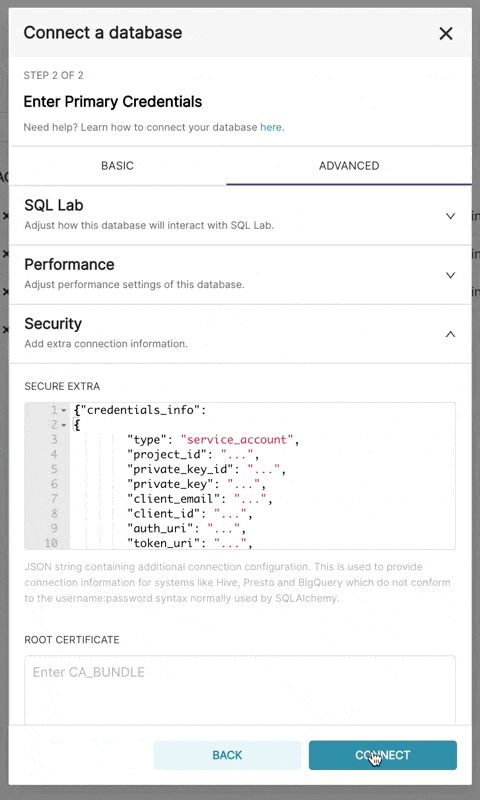
}生成的文件应具有此结构
{
"credentials_info": {
"type": "service_account",
"project_id": "...",
"private_key_id": "...",
"private_key": "...",
"client_email": "...",
"client_id": "...",
"auth_uri": "...",
"token_uri": "...",
"auth_provider_x509_cert_url": "...",
"client_x509_cert_url": "..."
}
}
然后您应该能够连接到您的 BigQuery 数据集。
为了能够在 Superset 中将 CSV 或 Excel 文件上传到 BigQuery,您还需要添加 pandas_gbq 库。
目前,Google BigQuery Python SDK 与 gevent 不兼容,因为 gevent 对 python 核心库进行了一些动态猴子补丁。因此,当您使用 gunicorn 服务器部署 Superset 时,您必须使用除 gevent 之外的工作类型。
Google Sheets
Google Sheets 的 SQL API 功能非常有限。Google Sheets 推荐的连接器库是 shillelagh。
将 Superset 连接到 Google Sheets 涉及几个步骤。这篇教程包含最新设置此连接的说明。
Hana
推荐的连接器库是 sqlalchemy-hana。
连接字符串格式如下
hana://{username}:{password}@{host}:{port}
Apache Hive
pyhive 库是推荐通过 SQLAlchemy 连接到 Hive 的方式。
预期的连接字符串格式如下
hive://hive@{hostname}:{port}/{database}
Hologres
Hologres 是阿里云开发的一款实时交互式分析服务。它完全兼容 PostgreSQL 11,并与大数据生态系统无缝集成。
Hologres 连接参数示例
- User Name: 您的阿里云账号的 AccessKey ID。
- Password: 您的阿里云账号的 AccessKey Secret。
- Database Host: Hologres 实例的公网端点。
- Database Name: Hologres 数据库的名称。
- Port: Hologres 实例的端口号。
连接字符串如下
postgresql+psycopg2://{username}:{password}@{host}:{port}/{database}
IBM DB2
IBM_DB_SA 库提供了到 IBM Data Servers 的 Python / SQLAlchemy 接口。
以下是推荐的连接字符串
db2+ibm_db://{username}:{passport}@{hostname}:{port}/{database}
SQLAlchemy 中实现了两个 DB2 方言版本。如果您连接的 DB2 版本不支持 LIMIT [n] 语法,则推荐的连接字符串以便使用 SQL Lab 的是
ibm_db_sa://{username}:{passport}@{hostname}:{port}/{database}
Apache Impala
连接 Apache Impala 推荐的连接器库是 impyla。
预期的连接字符串格式如下
impala://{hostname}:{port}/{database}
Kusto
Kusto 推荐的连接器库是 sqlalchemy-kusto>=2.0.0。
Kusto (sql 方言) 的连接字符串如下所示
kustosql+https://{cluster_url}/{database}?azure_ad_client_id={azure_ad_client_id}&azure_ad_client_secret={azure_ad_client_secret}&azure_ad_tenant_id={azure_ad_tenant_id}&msi=False
Kusto (kql 方言) 的连接字符串如下所示
kustokql+https://{cluster_url}/{database}?azure_ad_client_id={azure_ad_client_id}&azure_ad_client_secret={azure_ad_client_secret}&azure_ad_tenant_id={azure_ad_tenant_id}&msi=False
确保用户有权限访问和使用所有必需的数据库/表/视图。
Apache Kylin
Apache Kylin 推荐的连接器库是 kylinpy。
预期的连接字符串格式如下
kylin://<username>:<password>@<hostname>:<port>/<project>?<param1>=<value1>&<param2>=<value2>
MySQL
MySQL 推荐的连接器库是 mysqlclient。
连接字符串如下
mysql://{username}:{password}@{host}/{database}
主机
- 对于 Localhost:
localhost或127.0.0.1 - 在 Linux 上运行的 Docker:
172.18.0.1 - 对于本地部署: IP 地址或主机名
- 对于在 OSX 上运行的 Docker:
docker.for.mac.host.internal端口: 默认3306
mysqlclient 的一个问题是,它无法连接到使用 caching_sha2_password 进行身份验证的较新 MySQL 数据库,因为客户端中不包含该插件。在这种情况下,您应该改用 mysql-connector-python
mysql+mysqlconnector://{username}:{password}@{host}/{database}
IBM Netezza Performance Server
nzalchemy 库提供了到 IBM Netezza Performance Server (又称 Netezza) 的 Python / SQLAlchemy 接口。
以下是推荐的连接字符串
netezza+nzpy://{username}:{password}@{hostname}:{port}/{database}
OceanBase
sqlalchemy-oceanbase 库是推荐通过 SQLAlchemy 连接到 OceanBase 的方式。
OceanBase 的连接字符串如下所示
oceanbase://<User>:<Password>@<Host>:<Port>/<Database>
Ocient DB
Ocient 推荐的连接器库是 sqlalchemy-ocient。
安装 Ocient 驱动程序
pip install sqlalchemy-ocient
连接到 Ocient
Ocient DSN 的格式是
ocient://user:password@[host][:port][/database][?param1=value1&...]
Oracle
推荐的连接器库是 cx_Oracle。
连接字符串格式如下
oracle://<username>:<password>@<hostname>:<port>
Parseable
Parseable 是一个分布式日志分析数据库,为日志数据提供类似 SQL 的查询接口。推荐的连接器库是 sqlalchemy-parseable。
连接字符串格式如下
parseable://<username>:<password>@<hostname>:<port>/<stream_name>
例如
parseable://admin:admin@demo.parseable.com:443/ingress-nginx
注意:URI 中的 stream_name 代表您想要查询的 Parseable 日志流。您可以使用 HTTP(端口 80)和 HTTPS(端口 443)连接。
Apache Pinot
Apache Pinot 推荐的连接器库是 pinotdb。
预期的连接字符串格式如下
pinot+http://<pinot-broker-host>:<pinot-broker-port>/query?controller=http://<pinot-controller-host>:<pinot-controller-port>/``
使用用户名和密码的预期连接字符串格式如下
pinot://<username>:<password>@<pinot-broker-host>:<pinot-broker-port>/query/sql?controller=http://<pinot-controller-host>:<pinot-controller-port>/verify_ssl=true``
如果您想使用探索视图或连接、窗口函数等,请启用多阶段查询引擎。在“高级” -> “其他” -> “引擎参数”中创建数据库连接时,添加以下参数
{"connect_args":{"use_multistage_engine":"true"}}
Postgres
请注意,如果您正在使用 docker compose,Postgres 连接器库 psycopg2 是 Superset 开箱即用的。
Postgres 连接参数示例
- User Name: 用户名
- Password: 数据库密码
- 数据库主机:
- 对于 Localhost: localhost 或 127.0.0.1
- 对于本地部署: IP 地址或主机名
- 对于 AWS 端点
- Database Name: 数据库名称
- Port: 默认 5432
连接字符串如下
postgresql://{username}:{password}@{host}:{port}/{database}
您可以通过在末尾添加 ?sslmode=require 来要求 SSL
postgresql://{username}:{password}@{host}:{port}/{database}?sslmode=require
您可以从本文档的表 31-1中阅读有关 Postgres 支持的其他 SSL 模式的信息。
有关 PostgreSQL 连接选项的更多信息,请参见 SQLAlchemy 文档和 PostgreSQL 文档。
Presto
pyhive 库是推荐通过 SQLAlchemy 连接到 Presto 的方式。
预期的连接字符串格式如下
presto://{hostname}:{port}/{database}
您也可以传入用户名和密码
presto://{username}:{password}@{hostname}:{port}/{database}
以下是一个带值的连接字符串示例
presto://datascientist:securepassword@presto.example.com:8080/hive
默认情况下,Superset 假定在查询数据源时使用的是最新版本的 Presto。如果您使用的是旧版本的 Presto,您可以在 extra 参数中进行配置
{
"version": "0.123"
}
SSL 安全额外添加 JSON 配置到额外连接信息。
{
"connect_args":
{"protocol": "https",
"requests_kwargs":{"verify":false}
}
}
RisingWave
RisingWave 推荐的连接器库是 sqlalchemy-risingwave。
预期的连接字符串格式如下
risingwave://root@{hostname}:{port}/{database}?sslmode=disable
Rockset
Rockset 的连接字符串是
rockset://{api key}:@{api server}
从 Rockset 控制台获取您的 API 密钥。从 API 参考中找到您的 API 服务器。省略 URL 的 https:// 部分。
要定位到特定的虚拟实例,请使用此 URI 格式
rockset://{api key}:@{api server}/{VI ID}
有关更完整的说明,我们推荐查阅 Rockset 文档。
Snowflake
安装 Snowflake 驱动程序
按照此处的步骤了解如何在通过 docker compose 本地设置 Superset 时安装新的数据库驱动程序。
echo "snowflake-sqlalchemy" >> ./docker/requirements-local.txt
Snowflake 推荐的连接器库是 snowflake-sqlalchemy。
Snowflake 的连接字符串如下所示
snowflake://{user}:{password}@{account}.{region}/{database}?role={role}&warehouse={warehouse}
连接字符串中无需指定 schema,因为它是在每个表/查询中定义的。如果为用户定义了默认值,则可以省略 role 和 warehouse,例如:
snowflake://{user}:{password}@{account}.{region}/{database}
确保用户具有访问和使用所有必需的数据库/模式/表/视图/仓库的权限,因为 Snowflake SQLAlchemy 引擎默认在引擎创建期间不测试用户/角色权限。但是,在“创建或编辑数据库”对话框中按下“测试连接”按钮时,通过在引擎创建期间将“validate_default_parameters”: True 传递给 connect() 方法来验证用户/角色凭据。如果用户/角色未被授权访问数据库,则会在 Superset 日志中记录错误。
如果您想使用 密钥对认证连接 Snowflake。请确保您拥有密钥对,并且公钥已在 Snowflake 中注册。要使用密钥对认证连接 Snowflake,您需要在“SECURE EXTRA”字段中添加以下参数。
请注意,您需要将多行私钥内容合并为一行,并在每行之间插入 \n
{
"auth_method": "keypair",
"auth_params": {
"privatekey_body": "-----BEGIN ENCRYPTED PRIVATE KEY-----\n...\n...\n-----END ENCRYPTED PRIVATE KEY-----",
"privatekey_pass":"Your Private Key Password"
}
}
如果您的私钥存储在服务器上,您可以在参数中用“privatekey_path”替换“privatekey_body”。
{
"auth_method": "keypair",
"auth_params": {
"privatekey_path":"Your Private Key Path",
"privatekey_pass":"Your Private Key Password"
}
}
Apache Solr
sqlalchemy-solr 库提供了到 Apache Solr 的 Python / SQLAlchemy 接口。
Solr 的连接字符串如下所示
solr://{username}:{password}@{host}:{port}/{server_path}/{collection}[/?use_ssl=true|false]
Apache Spark SQL
Apache Spark SQL 推荐的连接器库是 pyhive。
预期的连接字符串格式如下
hive://hive@{hostname}:{port}/{database}
SQL Server
SQL Server 推荐的连接器库是 pymssql。
SQL Server 的连接字符串如下所示
mssql+pymssql://<Username>:<Password>@<Host>:<Port-default:1433>/<Database Name>
也可以使用 pyodbc 和参数 odbc_connect 进行连接
SQL Server 的连接字符串如下所示
mssql+pyodbc:///?odbc_connect=Driver%3D%7BODBC+Driver+17+for+SQL+Server%7D%3BServer%3Dtcp%3A%3Cmy_server%3E%2C1433%3BDatabase%3Dmy_database%3BUid%3Dmy_user_name%3BPwd%3Dmy_password%3BEncrypt%3Dyes%3BConnection+Timeout%3D30
您可能已经注意到,上述连接字符串中使用了某些特殊字符。例如,请参见 odbc_connect 参数。其值为 Driver%3D%7BODBC+Driver+17+for+SQL+Server%7D%3B,这是 Driver={ODBC+Driver+17+for+SQL+Server}; 的 URL 编码形式。重要的是连接字符串必须进行 URL 编码。
有关此问题的更多信息,请查阅 SQLAlchemy 文档。其中指出:“构建要传递给 create_engine() 的完整 URL 字符串时,用户和密码中可能使用的特殊字符(例如 @ 符号)需要进行 URL 编码才能正确解析。”
SingleStore
SingleStore 推荐的连接器库是 sqlalchemy-singlestoredb。
预期的连接字符串格式如下
singlestoredb://{username}:{password}@{host}:{port}/{database}
StarRocks
sqlalchemy-starrocks 库是推荐通过 SQLAlchemy 连接到 StarRocks 的方式。
您需要以下设置值来形成连接字符串
- User: 用户名
- Password: 数据库密码
- Host: StarRocks FE 主机
- Catalog: 目录名称
- Database: 数据库名称
- Port: StarRocks FE 端口
连接字符串如下所示
starrocks://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database>
StarRocks 在此处维护其 Superset 文档。
TDengine
TDengine 是一款高性能、可扩展的工业物联网时序数据库,并提供类 SQL 的查询接口。
TDengine 推荐的连接器库是 taospy 和 taos-ws-py
预期的连接字符串格式如下
taosws://<user>:<password>@<host>:<port>
例如
taosws://root:taosdata@127.0.0.1:6041
Teradata
推荐的连接器库是 teradatasqlalchemy。
Teradata 的连接字符串如下所示
teradatasql://{user}:{password}@{host}
ODBC 驱动程序
还有一个名为 sqlalchemy-teradata 的旧版连接器,它需要安装 ODBC 驱动程序。Teradata ODBC 驱动程序可在此处获取:https://downloads.teradata.com/download/connectivity/odbc-driver/linux
以下是所需的环境变量
export ODBCINI=/.../teradata/client/ODBC_64/odbc.ini
export ODBCINST=/.../teradata/client/ODBC_64/odbcinst.ini
我们建议使用第一个库,因为它不需要 ODBC 驱动程序,并且更新更频繁。
TimescaleDB
TimescaleDB 是用于时序和分析的开源关系数据库,用于构建强大的数据密集型应用程序。TimescaleDB 是 PostgreSQL 的一个扩展,您可以使用标准的 PostgreSQL 连接器库 psycopg2 连接到数据库。
如果您使用 docker compose,psycopg2 会随 Superset 开箱即用。
TimescaleDB 连接参数示例
- User Name: 用户
- Password: 密码
- 数据库主机:
- 对于 Localhost: localhost 或 127.0.0.1
- 对于本地部署: IP 地址或主机名
- 对于 Timescale Cloud 服务: 主机名
- 对于 Managed Service for TimescaleDB 服务: 主机名
- Database Name: 数据库名称
- Port: 默认 5432 或服务的端口号
连接字符串如下
postgresql://{username}:{password}@{host}:{port}/{database name}
您可以通过在末尾添加 ?sslmode=require 来要求 SSL(例如,如果您使用 Timescale Cloud)
postgresql://{username}:{password}@{host}:{port}/{database name}?sslmode=require
Trino
支持 Trino 版本 352 及更高
连接字符串
连接字符串格式如下
trino://{username}:{password}@{hostname}:{port}/{catalog}
如果您在本地机器上使用 docker 运行 Trino,请使用以下连接 URL
trino://trino@host.docker.internal:8080
认证
1. 基本认证
您可以在连接字符串中或在“高级 / 安全”下的“安全额外”字段中提供 username/password
-
在连接字符串中
trino://{username}:{password}@{hostname}:{port}/{catalog} -
在
Secure Extra字段中{
"auth_method": "basic",
"auth_params": {
"username": "<username>",
"password": "<password>"
}
}
注意:如果两者都提供,Secure Extra 始终具有更高优先级。
2. Kerberos 认证
在 Secure Extra 字段中,配置如下示例
{
"auth_method": "kerberos",
"auth_params": {
"service_name": "superset",
"config": "/path/to/krb5.config",
...
}
}
auth_params 中的所有字段都直接传递给 KerberosAuthentication 类。
注意:Kerberos 身份验证需要本地安装带有 all 或 kerberos 可选功能的 trino-python-client,即分别安装 trino[all] 或 trino[kerberos]。
3. 证书认证
在 Secure Extra 字段中,配置如下示例
{
"auth_method": "certificate",
"auth_params": {
"cert": "/path/to/cert.pem",
"key": "/path/to/key.pem"
}
}
auth_params 中的所有字段都直接传递给 CertificateAuthentication 类。
4. JWT 认证
配置 auth_method 并在 Secure Extra 字段中提供令牌
{
"auth_method": "jwt",
"auth_params": {
"token": "<your-jwt-token>"
}
}
5. 自定义认证
要使用自定义身份验证,首先您需要在 Superset 配置文件中将其添加到 ALLOWED_EXTRA_AUTHENTICATIONS 允许列表中
from your.module import AuthClass
from another.extra import auth_method
ALLOWED_EXTRA_AUTHENTICATIONS: Dict[str, Dict[str, Callable[..., Any]]] = {
"trino": {
"custom_auth": AuthClass,
"another_auth_method": auth_method,
},
}
然后在 Secure Extra 字段中
{
"auth_method": "custom_auth",
"auth_params": {
...
}
}
您还可以通过将对 trino.auth.Authentication 类或工厂函数(返回 Authentication 实例)的引用提供给 auth_method 来使用自定义身份验证。
auth_params 中的所有字段都直接传递给您的类/函数。
参考:
Vertica
推荐的连接器库是 sqlalchemy-vertica-python。 Vertica 连接参数为
- User Name: 用户名
- Password: 数据库密码
- 数据库主机
- 对于 Localhost : localhost 或 127.0.0.1
- 对于本地部署 : IP 地址或主机名
- 对于云端: IP 地址或主机名
- Database Name: 数据库名称
- Port: 默认 5433
连接字符串格式如下
vertica+vertica_python://{username}:{password}@{host}/{database}
其他参数
- 负载均衡器 - 备用主机
YDB
YDB 推荐的连接器库是 ydb-sqlalchemy。
连接字符串
YDB 的连接字符串如下所示
ydb://{host}:{port}/{database_name}
协议
您可以在“高级 / 安全”下的“安全额外”字段中指定 protocol
{
"protocol": "grpcs"
}
默认值为 grpc。
认证方法
静态凭证
要使用 Static Credentials,您应该在“高级 / 安全”下的“安全额外”字段中提供 username/password
{
"credentials": {
"username": "...",
"password": "..."
}
}
访问令牌凭证
要使用 Access Token Credentials,您应该在“高级 / 安全”下的“安全额外”字段中提供 token
{
"credentials": {
"token": "...",
}
}
服务账户凭证
要使用服务账户凭据,您应该在“高级 / 安全”下的“安全额外”字段中提供 service_account_json
{
"credentials": {
"service_account_json": {
"id": "...",
"service_account_id": "...",
"created_at": "...",
"key_algorithm": "...",
"public_key": "...",
"private_key": "..."
}
}
}
YugabyteDB
YugabyteDB 是一个基于 PostgreSQL 构建的分布式 SQL 数据库。
请注意,如果您正在使用 docker compose,Postgres 连接器库 psycopg2 是 Superset 开箱即用的。
连接字符串如下
postgresql://{username}:{password}@{host}:{port}/{database}
通过 UI 连接
这是关于如何利用新 DB 连接 UI 的文档。这将使管理员能够为想要连接到新数据库的用户增强用户体验。
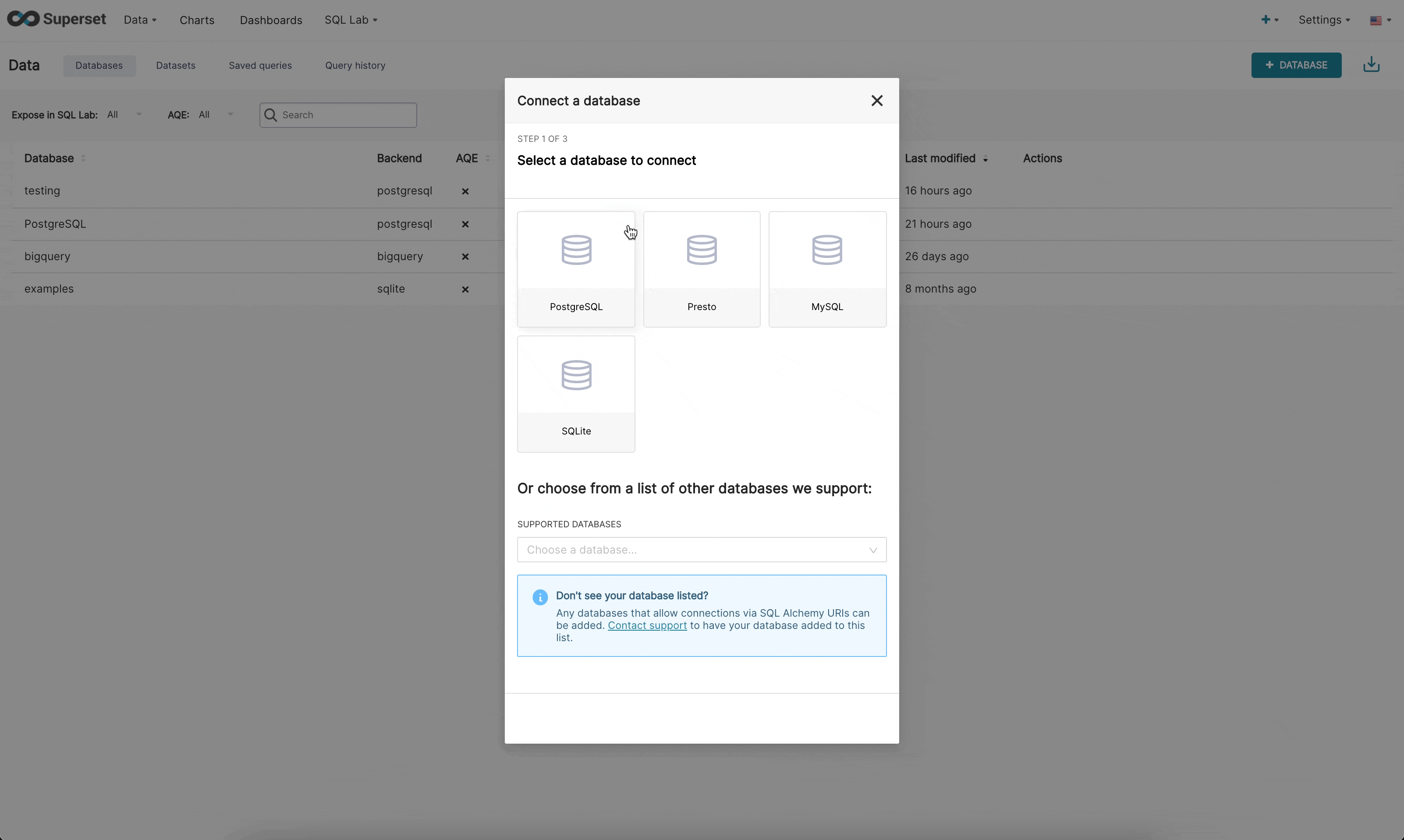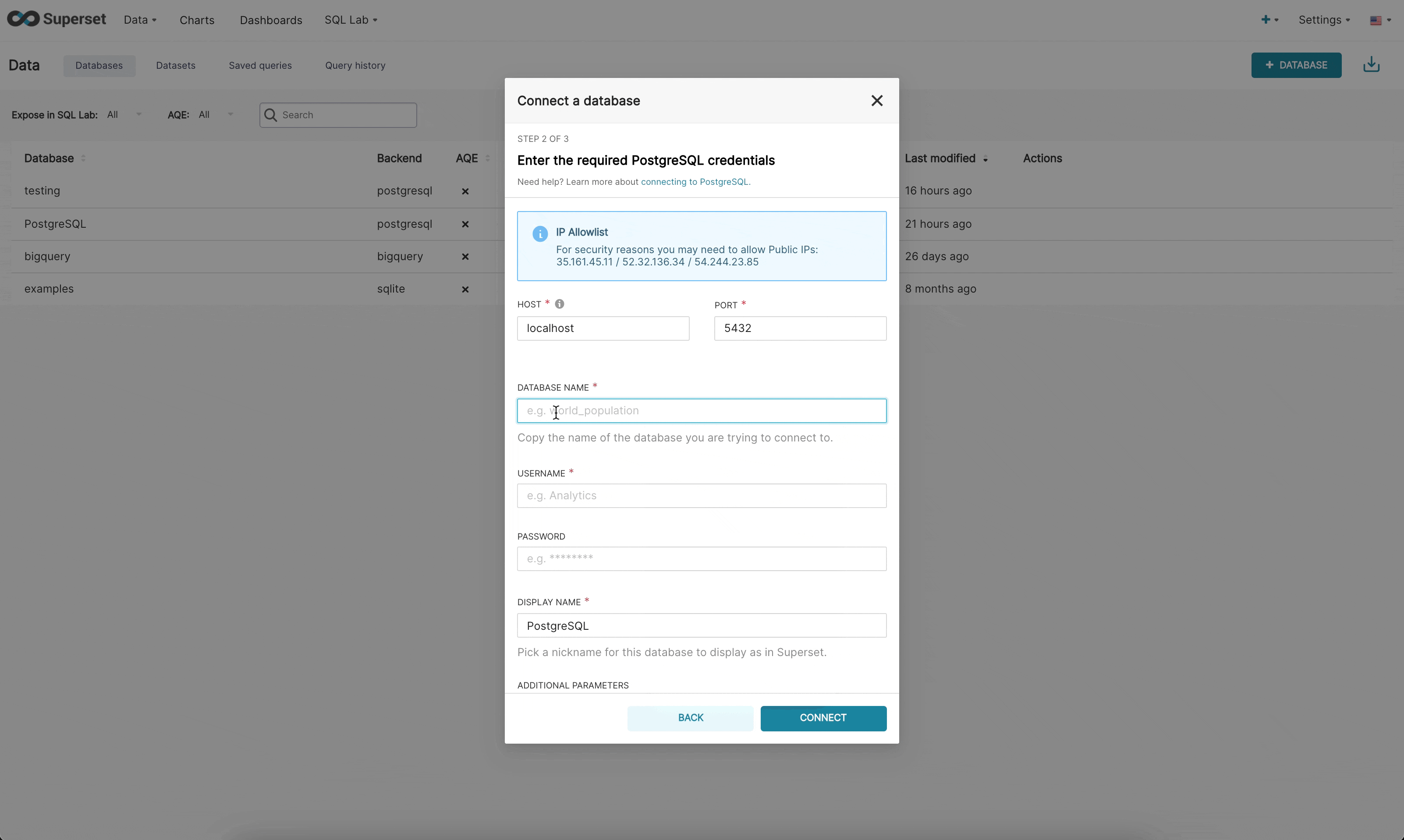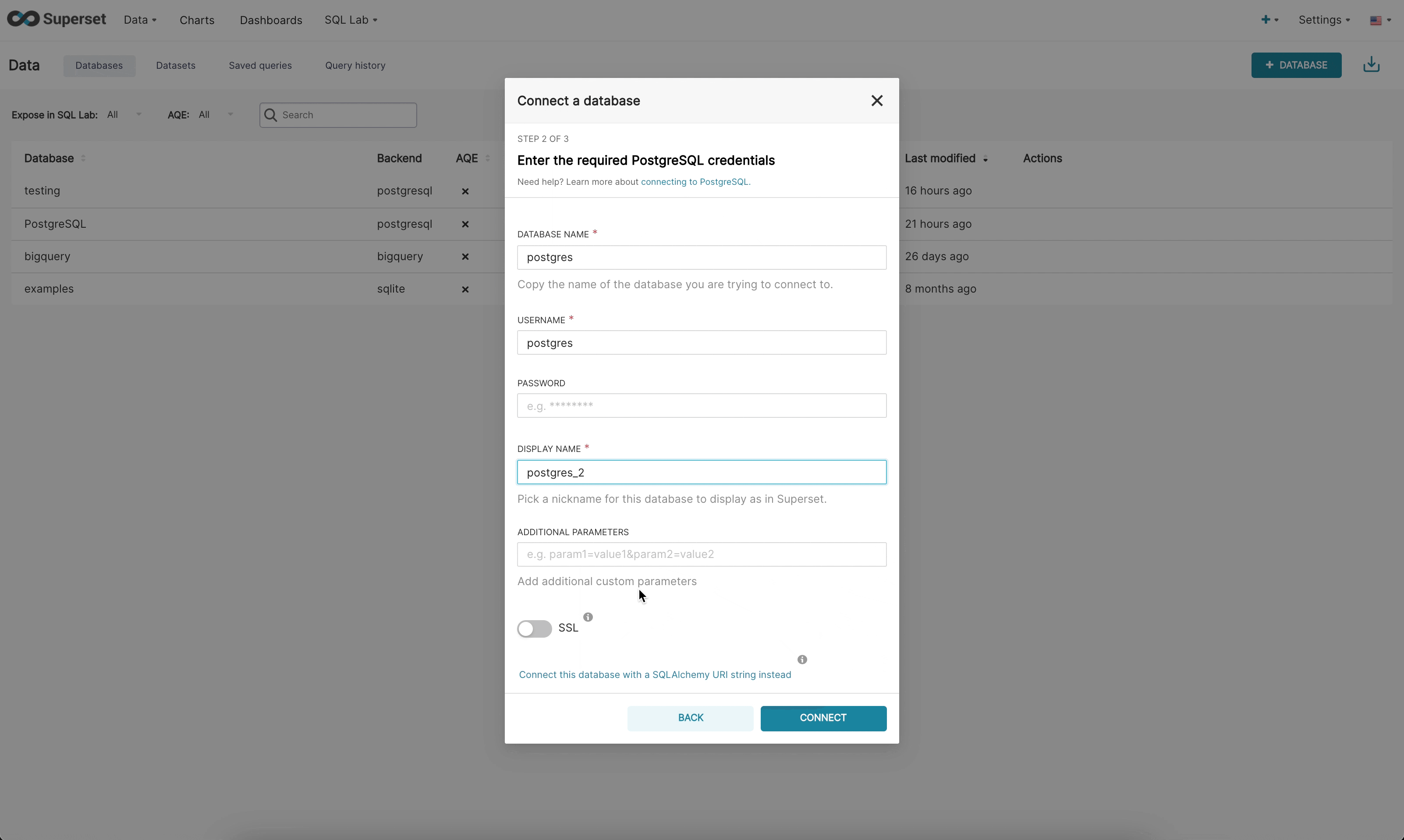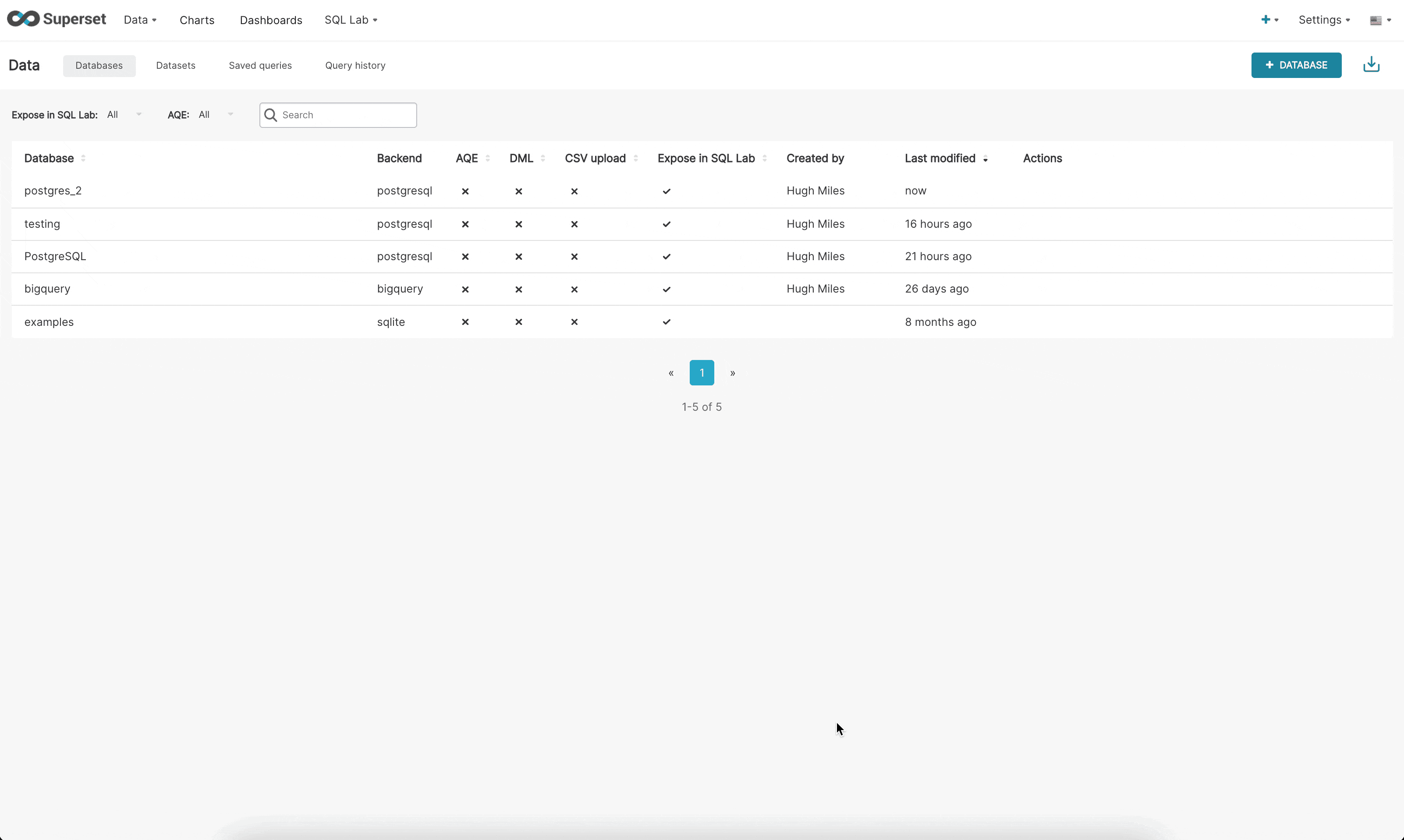
现在,在新的 UI 中连接到数据库有 3 个步骤
步骤 1:首先,管理员必须告知 Superset 他们想要连接的引擎。此页面由 /available 端点提供支持,该端点从您环境中当前安装的引擎中提取信息,以便仅显示受支持的数据库。
步骤 2:接下来,提示管理员输入数据库特定参数。根据该特定引擎是否有可用的动态表单,管理员将看到新的自定义表单或旧版 SQLAlchemy 表单。我们目前已为(Redshift、MySQL、Postgres 和 BigQuery)构建了动态表单。新表单会提示用户输入连接所需的参数(例如,用户名、密码、主机、端口等),并提供即时错误反馈。
步骤 3:最后,一旦管理员使用动态表单连接到他们的数据库,他们就有机会更新任何可选的高级设置。
我们希望此功能有助于消除用户进入应用程序并开始创建数据集的巨大瓶颈。
如何设置首选数据库选项和图片
我们添加了一个新的配置选项,管理员可以在其中按顺序定义他们的首选数据库
# A list of preferred databases, in order. These databases will be
# displayed prominently in the "Add Database" dialog. You should
# use the "engine_name" attribute of the corresponding DB engine spec
# in `superset/db_engine_specs/`.
PREFERRED_DATABASES: list[str] = [
"PostgreSQL",
"Presto",
"MySQL",
"SQLite",
]
出于版权原因,每个数据库的标志不随 Superset 分发。
设置图片
- 要设置首选数据库的图像,管理员必须在
superset_text.yml文件中创建一个包含引擎和图像位置的映射。图像可以本地托管在您的 static/file 目录中,也可以在线托管(例如 S3)
DB_IMAGES:
postgresql: "path/to/image/postgres.jpg"
bigquery: "path/to/s3bucket/bigquery.jpg"
snowflake: "path/to/image/snowflake.jpg"
如何将新的数据库引擎添加到可用端点
目前新模态支持以下数据库
- Postgres
- Redshift
- MySQL
- BigQuery
当用户选择不在列表中的数据库时,他们将看到旧的对话框,要求输入 SQLAlchemy URI。可以逐步将新的数据库添加到新流程中。为了支持丰富的配置,数据库引擎规范需要具有以下属性
parameters_schema: 一个 Marshmallow schema,定义配置数据库所需的参数。对于 Postgres,这包括用户名、密码、主机、端口等(参见)。default_driver: DB 引擎规范的推荐驱动程序的名称。许多 SQLAlchemy 方言支持多个驱动程序,但通常有一个是官方推荐的。对于 Postgres,我们使用 "psycopg2"。sqlalchemy_uri_placeholder: 一个字符串,用于帮助用户在他们希望直接输入 URI 的情况下。encryption_parameters: 当用户选择加密连接时用于构建 URI 的参数。对于 Postgres,这是{"sslmode": "require"}。
此外,DB 引擎规范必须实现这些类方法
build_sqlalchemy_uri(cls, parameters, encrypted_extra): 此方法接收不同的参数并从中构建 URI。get_parameters_from_uri(cls, uri, encrypted_extra): 此方法执行相反的操作,从给定的 URI 中提取参数。validate_parameters(cls, parameters): 此方法用于表单的onBlur验证。它应返回一个SupersetError列表,指示缺少哪些参数以及哪些参数肯定不正确(示例)。
对于 MySQL 和 Postgres 等使用标准格式 engine+driver://user:password@host:port/dbname 的数据库,您只需将 BasicParametersMixin 添加到 DB 引擎规范中,然后定义参数 2-4(parameters_schema 已经存在于 mixin 中)。
对于其他数据库,您需要自己实现这些方法。BigQuery DB 引擎规范是一个很好的示例,说明如何做到这一点。
额外数据库设置
更深入的 SQLAlchemy 集成
可以通过 SQLAlchemy 暴露的参数来调整数据库连接信息。在**数据库编辑**视图中,您可以将**额外**字段编辑为 JSON blob。
此 JSON 字符串包含额外的配置元素。engine_params 对象被解包到 sqlalchemy.create_engine 调用中,而 metadata_params 则被解包到 sqlalchemy.MetaData 调用中。有关更多信息,请参阅 SQLAlchemy 文档。
Schema
像 Postgres 和 Redshift 这样的数据库使用**schema**作为**database**之上的逻辑实体。为了让 Superset 连接到特定的 schema,您可以在**编辑表**表单中设置**schema**参数(源 > 表 > 编辑记录)。
SQLAlchemy 连接的外部密码存储
Superset 可以配置为使用外部存储来存储数据库密码。如果您正在运行自定义的秘密分发框架,并且不希望将秘密存储在 Superset 的元数据库中,这将非常有用。
示例:编写一个函数,它接受一个 sqla.engine.url 类型的参数,并返回给定连接字符串的密码。然后,在您的配置文件中将 SQLALCHEMY_CUSTOM_PASSWORD_STORE 设置为指向该函数。
def example_lookup_password(url):
secret = <<get password from external framework>>
return 'secret'
SQLALCHEMY_CUSTOM_PASSWORD_STORE = example_lookup_password
一种常见的模式是使用环境变量来提供秘密。SQLALCHEMY_CUSTOM_PASSWORD_STORE 也可以用于此目的。
def example_password_as_env_var(url):
# assuming the uri looks like
# mysql://?superset_user:{SUPERSET_PASSWORD}
return url.password.format(**os.environ)
SQLALCHEMY_CUSTOM_PASSWORD_STORE = example_password_as_env_var
数据库的 SSL 访问
您可以使用编辑数据库表单中的Extra字段来配置SSL
{
"metadata_params": {},
"engine_params": {
"connect_args":{
"sslmode":"require",
"sslrootcert": "/path/to/my/pem"
}
}
}
杂项
跨数据库查询
Superset 提供了一个实验性功能,用于跨不同数据库进行查询。这通过一个名为“Superset 元数据库”的特殊数据库实现,该数据库使用“superset://” SQLAlchemy URI。使用该数据库时,可以使用以下语法查询任何已配置数据库中的任何表
SELECT * FROM "database name.[[catalog.].schema].table name";
例如
SELECT * FROM "examples.birth_names";
允许存在空格,但名称中的句点必须替换为%2E。例如
SELECT * FROM "Superset meta database.examples%2Ebirth_names";
上面的查询返回与SELECT * FROM "examples.birth_names"相同的行,并且还表明元数据库可以查询任何表(甚至它自身!)中的表。
注意事项
在启用此功能之前,您应考虑以下几点。首先,元数据库对查询的表强制执行权限,因此用户只能通过数据库访问他们原本有权访问的表。尽管如此,元数据库是一个潜在攻击的新表面,并且错误可能允许用户查看他们不应查看的数据。
其次,存在性能方面的考虑。元数据库会将任何过滤、排序和限制操作推送到底层数据库,但任何聚合和连接操作将在运行查询的过程中在内存中进行。因此,建议在异步模式下运行数据库,以便查询在 Celery worker 中执行,而不是在 Web worker 中执行。此外,可以指定从底层数据库返回的行数的硬性限制。
启用元数据库
要启用 Superset 元数据库,首先需要将ENABLE_SUPERSET_META_DB功能标志设置为 true。然后,添加一个类型为“Superset 元数据库”的新数据库,其 SQLAlchemy URI 为“superset://”。
如果您在元数据库中启用 DML,用户将能够在底层数据库上运行 DML 查询,前提是这些数据库也启用了 DML。这允许用户运行跨数据库移动数据的查询。
其次,您可能需要更改SUPERSET_META_DB_LIMIT的值。默认值为 1000,它定义了在执行任何聚合和连接之前从每个数据库读取的行数。如果您的表都很小,您也可以将此值设置为None。
此外,您可能需要限制元数据库可以访问的数据库。这可以在数据库配置中,在“高级” -> “其他” -> “引擎参数”下完成,并添加
{"allowed_dbs":["Google Sheets","examples"]}